俁丏扵嶕朄
懳徾偲側傞栤戣傪偆傑偔扵嶕栘乮枖偼桳岦僌儔僼乯偲偟偰昞尰偱偒偨傜崱搙偼偦偺扵嶕栘傪埲壓偵岠棪傛偔挷傋傞偐偑栤戣偵側傝傑偡丅偙傟偑扵嶕偺栤戣偱偡丅扵嶕偵偼愡揰傪堦偮偢偮挷傋偰偄偔昁梫偑偁傝傑偡偑丄僑乕儖乮媮傔偨偄夝乯偵偨偳傝偮偔傑偱偵側傞傋偔彮側偄寁嶼検偱峴偔偙偲偑偱偒傟偽傛傝偄偄扵嶕朄偲側傝傑偡丅乮摉偨傝慜偱偡偹丅乯偮傑傝丄傛傝岠棪偺椙偄弴斣偱愡揰傪挷傋偰偄偔曽朄偑丄椙偄扵嶕朄偲偄偆傢偗偱偡丅
埲壓偱埖偆扵嶕朄偼丄扵嶕栘偵懳偟偰壗偺梊旛抦幆傕巊傢偢偵扵嶕傪峴偆扨弮側扵嶕乮僽儔僀儞僪扵嶕乯偲壗傜偐偺抦幆傪梡偄偨扵嶕乮僸儏乕儕僗僥傿僢僋扵嶕乯偺俀庬椶偑偁傝傑偡丅
扨弮側扵嶕朄丂乮僽儔僀儞僪扵嶕乯丂blind search抦幆傪梡偄側偄扨弮側扵嶕朄偺拞偱傕丄傕偭偲傕婎杮揑側傕偺偵廲宍扵嶕偲墶宍扵嶕偑偁傝傑偡丅偙偺擇偮偺曽朄偼旕忢偵扨弮側傾儖僑儕僘儉側偺偱嶌傞偺傕娙扨偱偡偑丄摉慠惈擻傕偦傟側傝偱偡丅
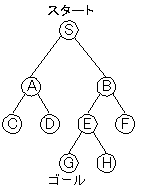
恾俁丏侾丂扵嶕栘偺椺 廲宍扵嶕丂乮怺偝桪愭扵嶕乯丂DFS : depth-first search
巬傪愭偵恑傔傞偐偓傝孈傝恑傔偰丄峴偒媗傑偭偨傜師偺巬傪挷傋傞偲偄偆曽朄偑廲宍扵嶕偱偡丅恾俁丏侾偺扵嶕栘偵懳偟偰扵嶕傪峴偆応崌偵偮偄偰峫偊偰傒傑偡丅
愭偵扵嶕寢壥傪帵偟偰偟偰偍偔偲丄
俽仺俙仺俠仺俢仺俛仺俤仺俧
偲偄偆弴斣偵愡揰傪挷傋偰偄偒傑偡丅
廲宍扵嶕偱偼栘偺怺偝傪桪愭偟偰扵嶕傪峴偆傢偗偱偡偐傜丄尰嵼奐偄偰偄傞乮尰嵼挷傋偨乯愡揰偵巕愡揰偑偁傞側傜丄偦偪傜偺愡揰傪愭偵挷傋偰偄偒傑偡丅扵嶕偼俽偐傜巒傑傞傢偗偱偡偑丄俽偵偼俙偲俛偺擇偮偺巕愡揰偑偁傝傑偡丅偙偙偱偼丄奐偔忦審偺摨偠愡揰偑暋悢偁傞応崌偵偼丄曋媂忋傾儖僼傽儀僢僩偺庒偄弴偵挷傋傞偙偲偵偟傑偡丅
偦偆偡傞偲丄俽偺師偵偼俙偑奐偐傟傞偙偲偵側傝傑偡丅偡傞偲俙偵偼俠偲俢偺擇偮偺巕愡揰偑偁傞偺偱偝傜偵怺偔恑傫偱丄俠傪挷傋傑偡丅崱搙偼俠偵偼巕愡揰偑側偔丄傑偨俠偼僑乕儖偱偼側偄偺偱丄堦偮栠偭偰俙偺傕偆堦偮偺巕愡揰偱偁傞俢傪挷傋傑偡丅偟偐偟丄俢偵傕巕愡揰偼側偔僑乕儖偱傕側偄偺偱丄俽傑偱栠偭偰俛傪奐偒傑偡丅偡傞偲巕愡揰俤偲俥偑尒偮偐傝傑偡丅偦偙偱傾儖僼傽儀僢僩弴偵俤傪奐偄偰傒傞偲丄俧偲俫偑巕愡揰偵偁傞偙偲偑傢偐傝傑偡丅偦偙偱丄偝傜偵怺偔恑傫偱丄俧傪奐偄偰尒傞偲偙傟偑栚揑偺僑乕儖偵偁偨傞愡揰偩偲傢偐傝傑偡丅偙傟偱扵嶕偼廔椆偱偡丅
崱夞偺椺偱偼丄俥偲俫偼挷傋偢偵嵪傒傑偟偨丅偟偐偟偁傑傝岠棪偑椙偄偲偼偄偊傑偣傫偹丅
傕偆彮偟傢偐傝傗偡偄傛偆偵丄open儕僗僩偲close儕僗僩傪彂偄偰傒傑偟傚偆丅open儕僗僩偲偼丄尰嵼奐偔偙偲偺偱偒傞愡揰偺儕僗僩偱丄捠忢偙偺儕僗僩偱慜偵偁傞傕偺偐傜奐偐傟傑偡丅close儕僗僩偲偼奐偄偰挷傋偰偟傑偭偨愡揰偺儕僗僩偱丄挷傋偍傢偭偨忬懺傪暵偠傞偲偟偰丄close儕僗僩偲偄偄傑偡丅
close ( )
摨偠怺偝偺愡揰傪挷傋廔傢偭偰偐傜師偺怺偝偵恑傓偲偄偆偺偑墶宍扵嶕偱偡丅恾俁丏侾偺扵嶕栘偵懳偟偰墶宍扵嶕傪峴偭偰傒傑偡丅
扵嶕寢壥偼丄
俽仺俙仺俛仺俠仺俢仺俤仺俥仺俧
偲側傝傑偡丅open儕僗僩偲close儕僗僩偼師偺傛偆偵側傝傑偡丅
俽偺巕愡揰偼俙偲俛側偺偱丄傑偢俙偑奐偐傟傑偡丅偡傞偲巕愡揰偼俠偲俢偑尒偮偐傞偺偱丄偙傟偼open儕僗僩偺俛偺屻傠偵捛壛偝傟傑偡丅師偵open儕僗僩偱堦斣慜偵偁傞偺偼俛側偺偱崱搙偼俛偑奐偐傟傑偡丅偙偙偱丄俤偲俥偑弌偰偔傞偺偱偙傟傪open儕僗僩偺屻傠偵捛壛偟傑偡丅偙偺傛偆偵丄墶宍扵嶕偱偼愭偵弌偰偒偨傕偺傎偳愭偵奐偐傟傑偡丅偙偺偨傔丄恾俁丏侾偺傛偆側扵嶕栘側傜丄傾儖僼傽儀僢僩弴偵奐偐傟偰偄偒傑偡丅
崱夞偺椺偱偼廲宍扵嶕偺傎偆偑墶宍扵嶕傛傝傕堦庤彮側偔僑乕儖偵偨偳傝偮偄偰偄傑偡丅堦斒偵扵嶕栘偼怺偄偑僑乕儖偼愺偄偲偙傠偵偁傞応崌偼墶宍扵嶕偺傎偆偑岠棪偑偄偄偲偄傢傟偰偄傑偡丅
偲偙傠偱丄傾儖僑儕僘儉乮僨乕僞峔憿乯偵徻偟偄恖偵偼丄廲宍扵嶕偼僗僞僢僋偱墶宍扵嶕偼僉儏乕偩偲尵偆偲傢偐傝傗偡偄偱偟傚偆偐丠
抦幆傪梡偄偨扵嶕丂乮僸儏乕儕僗僥傿僢僋扵嶕乯扵嶕栘傗丄桳岦僌儔僼偵壗傜偐偺僐僗僩偲偄偆傕偺偑傢偐傞応崌偵偼丄偙傟傪棙梡偟偰扵嶕傪峴偆偙偲偑峫偊傜傟傑偡丅椺偊偽丄愊傒栘偺栤戣偱偼愊傒栘傪摦偐偡偺偵偐偐傞帪娫偱偁傞偲偐僄僱儖僊乕偲偄偭偨傕偺偼丄忬懺乮奺忬懺偑愡揰偵偁偨傝傑偡乯傪曄壔偝偣傞偨傔偵巊傢傟傞僐僗僩偲偄偆傛偆偵峫偊傞偙偲偑偱偒傑偡丅偲偔偵丄偁傞忬懺偐傜栚揑偺忬懺傊曄壔偝偣傞傑偱偵丄暋悢偺曽朄偑偁傞傛偆側偲偒偵偼丄偳偺傛偆側宱楬傪偨偳偭偰丄栚揑偺忬懺傊帩偭偰偄偔偐偲偄偆偙偲偑丄扵嶕偺廳梫側栚揑偲側傞傢偗偱偡丅
愊傒栘偺栤戣側傜丄扨弮偵庤悢偑彮側偔栚揑偺愊傒曽偵摫偗傞傎偆偑偄偄偱偡偟丄柪楬傪夝偔栤戣側傜側傞傋偔抁偄宱楬傪捠偭偰僑乕儖傑偱峴偔傎偆偑偄偄偱偡偹丅
僐僗僩偑傢偐傞応崌丄忬懺傪曄壔偝偣傞偺偵偐偐傞僐僗僩偑傢偐傞応崌乮偮傑傝巬偺僐僗僩偑傢偐傞偲偄偆偙偲偱偡丅乯偲偦傟偧傟偺愡揰偐傜栚揑偺忬懺乮僑乕儖乯傑偱偺僐僗僩偑梊應偱偒傞応崌偺俀庬椶偑峫偊傜傟傑偡丅暯偨偔尵偆偲丄僗僞乕僩偐傜偺僐僗僩偺棜楌偑傢偐傞応崌偲丄奺抧揰偱偺僑乕儖傑偱偺僐僗僩偑梊應偱偒傞応崌偲偄偆偙偲偵側傝傑偡偹丅傕偪傠傫椉曽傢偐傞応崌傕峫偊傜傟傑偡丅
暘婒尷掕朄丂乮嵟揔夝偺扵嶕乯丂branch and bound (optimal-search)傑偢偼丄奺巬偺僐僗僩偑傢偐傞応崌偵偮偄偰峫偊偰傒傑偡丅偙偺傛偆側応崌丄僐僗僩偺嵟彮偲側傞宱楬傪尒偮偗傞偙偲偑偱偒傑偡丅奺愡揰傪奐偒巕愡揰傪open儕僗僩偵擖傟傞偲偒偵丄偦偙傑偱偺宱楬偺僐僗僩傪巊偭偰丄僐僗僩偺彫偝偄傕偺偑慜偵棃傞傛偆偵open儕僗僩傪暲傋捈偟偰傗傞偲丄偦偙傑偱偱僐僗僩偺堦斣彫偝側宱楬偑忢偵慖戰偝傟傞偙偲偵側傝傑偡丅偮傑傝丄梋寁側愡揰傪奐偔壜擻惈偼崅偄傕偺偺丄嵟屻偵摼傜傟傞宱楬偑嵟揔側傕偺偵側傞偲偄偆偺偑暘婒尷掕朄偱偡丅
暘婒尷掕朄偺摿挜偲偟偰丄桳岦僌儔僼偺傛偆偵僑乕儖傑偱偵暋悢偺宱楬傪慖傋傞傛偆側応崌偱傕丄僐僗僩嵟彮偺宱楬傪尒偮偗傞偙偲偑偱偒傑偡丅側偤側傜丄僐僗僩偑崅偔open儕僗僩拞偱屻傠偺傎偆偵偁傞愡揰偱傕丄偦偙傑偱偺怴偟偄宱楬偑尒偮偐偭偨偲偒丄偦偺宱楬偺傎偆偑僐僗僩偑掅偗傟偽丄怴偟偄宱楬傪偦偺愡揰傊偺摴偲偟偰婰榐偟捈偟傑偡丅偙偺偨傔丄open儕僗僩偵擖偭偰偄傞愡揰傑偱偺僐僗僩偼丄忢偵偦偺帪揰偱偺嵟彮偺僐僗僩偵側傝丄僑乕儖偵偨偳傝偮偄偨偲偒偵偼丄僑乕儖傑偱偺嵟彮偺僐僗僩偑媮傑偭偰偄傞偲偄偆傢偗偱偡丅
堦尵偱尵偆偲暘婒尷掕朄偼愡揰傑偱偺僐僗僩傪曐帩偟丄偦偺僐僗僩偑嵟彮偵側傞愡揰傪師偵揥奐偟偰偄偔傾儖僑儕僘儉偱偡丅
偦傟偱偼椺傪嫇偘偰傒傑偡丅
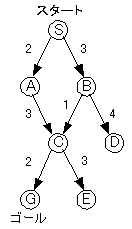
恾俁丏俀丂桳岦僌儔僼偺椺
乮仸巬偺墶偵偁傞悢帤偑偦偺巬偺僐僗僩偱偡乯
恾俁丏俀偺傛偆側桳岦僌儔僼偵懳偟偰暘婒尷掕朄傪梡偄傞偲丄open儕僗僩偼
偲側傝傑偡丅
俽傪揥奐偡傞偲偒偵偼乽俙偺恊偼俽乿乽俛偺恊偼俽乿偲偄偆忣曬傪婰榐偟傑偡丅傑偨丄俠偺傛偆側応崌偵偼丄俙偑揥奐偝傟偨偲偒偵乽俠偺恊偼俙乿偲婰榐偝傟偦偺偲偒丄俠傊偺僐僗僩偼俆偲婰榐偝傟傑偡偑丄偙偺屻丄俛偑揥奐偝傟傞偲僐僗僩偑係偱俠偵偨偳傝拝偔偺偱丄乽俠偺恊偼俛乿偲彂偒姺偊傜傟傑偡丅偦偟偰丄俠傊偺僐僗僩偑堦斣彫偝偄偺偱俠偑揥奐偝傟丄懕偄偰俧偑揥奐偝傟傑偡丅偙偙偱丄俧偺恊偼俠偱丄俠偺恊偼俛丄偦偺恊偼俽側偺偱丄
俽仺俛仺俠仺俧
偲偄偆宱楬偑傕偭偲傕僐僗僩偺掅偄宱楬偲偟偰摫偐傟傑偡丅
巬偺僐僗僩偑傢偐偭偰偄傞応崌偵偼暘婒尷掕朄偼忢偵嵟揔側宱楬傪敪尒偱偒傑偡丅
師偵奺愡揰偐傜僑乕儖傑偱偺僐僗僩偑梊應偱偒傞応崌偵巊偊傞庤朄傪徯夘偟傑偡丅
嶳搊傝朄丂乮岡攝崀壓朄乯丂hill climbing ( gradient descent )嶳搊傝朄偼旕忢偵扨弮側傾儖僑儕僘儉偱丄尰嵼偺愡揰偺巕愡揰慡偰偵偮偄偰丄僑乕儖傑偱偺梊應僐僗僩偑傕偭偲傕掅偄傕偺傪慖戰偟丄偦偺愡揰傪奐偒偦偺巕愡揰偺拞偱堦斣僐僗僩偺掅偄傕偺傪ゥ苽鄠虃艂穪B偙偺曽朄偼丄偦偺帪栚偺慜偵偁傞傕偺偺偆偪堦斣椙偄傕偺傪慖傃偮偯偗傞傾儖僑儕僘儉偲偄偊傑偡丅偙偺偨傔丄栤戣偺惈幙偵傛偭偰偼丄嵟揔側摎偊偳偙傠偐摎偊傑偱峴偒拝偗側偄偲偄偆応崌偡傜偁傝傑偡丅
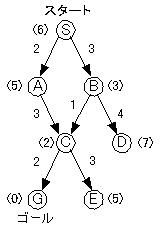
恾俁丏俁丂梊應僐僗僩偺偁傞桳岦僌儔僼偺椺
乮仸愡揰偺墶偵偁傞妵屖偺偮偄偨悢帤偑偦偺愡揰偺梊應僐僗僩偱偡乯
open儕僗僩偼
偲側傝傑偡丅
偙偺椺偼梊應僐僗僩偑幚嵺偺僐僗僩偲堦抳偟偰偄傞偨傔丄摼傜傟傞宱楬傕
俽仺俛仺俠仺俧
偲側偭偰偄偰丄嶳搊傝朄偑偆傑偔偄偔椺偱偡偑丄梊應僐僗僩偑娫堘偭偰偄偰俛偺梊應僐僗僩偑俇偵側偭偰偄偨傝偡傞偲open儕僗僩偼
偱丄摼傜傟傞宱楬偼
俽仺俙仺俠仺俧
偲側傝丄嵟揔側宱楬偱偼偁傝傑偣傫丅嵟埆偺応崌偵偼偄偮傑偱傕摨偠応強傪儖乕僾偟偰偟傑偆壜擻惈偡傜偁傝傑偡丅
嶳搊傝朄偱偼慖戰偝傟側偐偭偨愡揰偺忣曬偼偦偺傑傑攑婞偝傟偰偄傑偟偨偑丄偙偺愡揰偺忣曬傕曐帩偟偮偯偗偰崱傑偱偱堦斣傛偝偦偆側愡揰傪慖傇傛偆偵偟偨偺偑嵟椙桪愭扵嶕偱偡丅嵟椙桪愭扵嶕偱偼愡揰傪奐偒巕愡揰偑尒偮偐偭偨偲偒偵丄偦偺愡揰偑崱傑偱偵奐偄偨傕偺偐偳偆偐傕僠僃僢僋偡傞偺偱乮open儕僗僩偲close儕僗僩傪挷傋傞乯嶳搊傝朄偺傛偆偵儖乕僾偵娮偭偰偟傑偆偙偲傕偁傝傑偣傫丅偟偐偟丄梊應僐僗僩偵埶懚偟偰偄傞偨傔丄傗偼傝嵟揔宱楬偑尒偮偐傞曐徹偼偁傝傑偣傫丅
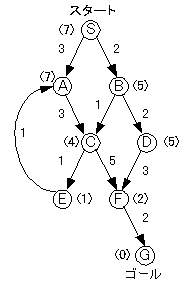
恾俁丏係丂儖乕僾偺壜擻惈偺偁傞桳岦僌儔僼偺椺
恾俁丏係偼嶳搊傝朄偱偼儖乕僾傪婲偙偟偰偟傑偆椺偱偡丅偙傟偵懳偟偰嵟椙桪愭扵嶕傪峴偆偲儖乕僾偵娮傜偢偵僑乕儖傑偱偨偳傝拝偔偙偲偑偱偒傑偡丅
嶳搊傝朄偺open儕僗僩
嵟椙桪愭扵嶕偺open儕僗僩
嶳搊傝朄偱偼俙仺俠仺俤仺俙偲偄偆儖乕僾傪夞傝懕偗偰偟傑偄傑偡偑丄嵟椙桪愭扵嶕偱偼丄
俽仺俛仺俠仺俥仺俧丂僐僗僩丗侾侽
偲偄偆宱楬傪尒偮偗偰僑乕儖傑偱偨偳傝拝偔偙偲偑偱偒傑偟偨丅
偟偐偟丄偙偙偱桳岦僌儔僼偺僐僗僩偵拲堄偟偰傒傞偲杮摉偺嵟揔宱楬偼
俽仺俛仺俢仺俥仺俧丂僐僗僩丗俋
偲偄偆宱楬偱偡丅偙傟偼幚嵺偺僐僗僩偲梊應僐僗僩偺娫偵僘儗偑偁傞偨傔偵慖戰偱偒側偐偭偨宱楬偱偡丅偟偐偟幚嵺偺栤戣偱僐僗僩傪姰慡偵梊應偡傞偙偲偼擄偟偔嵟椙桪愭扵嶕偱偼偙偺偁偨傝偑尷奅偺傛偆偱偡丅
嵟椙桪愭扵嶕偱偼栚昗乮僑乕儖乯傑偱偺梊應僐僗僩偼僗僞乕僩偐傜尰嵼偺愡揰傑偱偺僐僗僩偼峫椂偟偰偄傑偣傫偱偟偨丅偦偙偱丄愡揰偐傜僑乕儖傑偱偺僐僗僩偺梊應抣偲僗僞乕僩偐傜愡揰傑偱偺僐僗僩偺榓傪巊偭偰丄宱楬偺昡壙傪峴偄傑偡丅偮傑傝丄暘婒尷掕朄偲嵟椙桪愭扵嶕偺椉曽偺摿惈傪帩偭偰偄傞庤朄偱偡丅
傑偨丄俙傾儖僑儕僘儉偲俙仏傾儖僑儕僘儉偺堘偄偼丄梊應僐僗僩偑忦審傪枮偨偟偰偄傞偐偲偄偆揰偩偗偱偡丅梊應僐僗僩偑幚嵺偺僐僗僩偲斾傋偰丄摍偟偄偐傑偨偼丄幚嵺傛傝傕彫偝偔梊應偝傟偰偄傞応崌偵偼俙仏傾儖僑儕僘儉偲偄偄傑偡丅偦傟埲奜偺応崌偼俙傾儖僑儕僘儉偲側傝傑偡丅
俙傾儖僑儕僘儉偼丄嵟揔夝偑媮傑傞曐徹偼偁傝傑偣傫偑丄俙仏傾儖僑儕僘儉偺忦審傪枮偨偟偰偄傞応崌偵偼丄嵟揔夝偑媮傑傞偙偲偑曐徹偝傟偰偄傑偡丅
偙偺傾儖僑儕僘儉乮俙傑偨偼俙仏乯偼娙扨偵尵偆偲丄嵟椙桪愭扵嶕偱昡壙偵愡揰偺梊應僐僗僩傪梡偄偰偄偨偲偙傠傪丄愡揰偺梊應僐僗僩偵丄暘婒尷掕朄偺庤朄偱媮傔偨偦偺愡揰傑偱偺僐僗僩傪偨偟偨傕偺傪戙擖偟偰丄僐僗僩偺彫偝偄傕偺傪慖傇偲偄偆庤朄偱偡丅偨偩偟丄傕偆堦偮堘偆揰偑偁傝丄堦搙揥奐偟偰close儕僗僩偵擖傟傜傟偨愡揰偱傕昡壙僐僗僩傪曐帩偟丄怴偟偔尒偮偐偭偨宱楬偵傛傞昡壙僐僗僩偑close儕僗僩丂偺傕偺傛傝彫偝偗傟偽丄偦偺愡揰傪嵞傃open儕僗僩偵擖傟傑偡丅偙偆偡傞偙偲偱嵟揔夝偑摼傜傟傞偙偲傪曐徹偟偰偄傑偡丅
恾俁丏係偼梊應僐僗僩偑幚嵺偺僐僗僩偲摍偟偄偐彫偝偄偲偄偆忦審傪傒偨偄偟偰偄傞偺偱丄偙傟偵俙仏傾儖僑儕僘儉傪揔梡偡傞偲丄open儕僗僩偼
偲側傝丄俇庤偱嵟揔宱楬偱偁傞
俽仺俛仺俢仺俥仺俧丂僐僗僩丗俋
偑摼傜傟傑偡丅
偝偰丄偙偙偱俙仏傾儖僑儕僘儉偺忦審偑梊應僐僗僩偑幚嵺偲摍偟偄偐偦傟傛傝彫偝偄偲偄偆傕偺偱偟偨偑丄偙傟偼偳偆偄偆偙偲偐椺傪嫇偘偰傒偨偄偲巚偄傑偡丅
椺偊偽丄恾俁丏俆偺傛偆側柪楬偱僗僞乕僩偐傜僑乕儖傑偱偺宱楬傪扵嶕偡傞偲偒丄僐僗僩傪宱楬偺挿偝偲偟偰丄梊應僐僗僩偼嵗昗偐傜廲偺嫍棧偲墶偺嫍棧偺榓偲偡傞偲丄俙仏偺忦審偼忢偵枮偨偝傟傑偡丅偨偩偟丄偙偺応崌丄尰嵼偺嵗昗偑傢偐傞昁梫偑偁傝傑偡偑丅
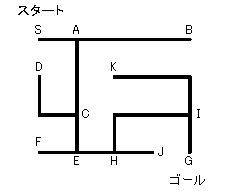
恾俁丏俆丂柪楬偺扵嶕偺椺
幚嵺偵抣傪弌偟偰傒傞偲丄俛偼梊應僐僗僩偼廲偵堦捈慄偱俁偲側傝傑偡偑丄幚嵺偺僐僗僩偼俙俠俤俫俬俧偲偨偳傞昁梫偑偁傞偺偱丄侾侾偲側傝傑偡丅俠側傜梊應僐僗僩偼廲侾偲墶俁偱崌寁係偲側傝傑偡偑丄幚嵺偼俤俫俬俧偲偨偳傞偺偱丄俇偲側傝傑偡丅偙偺擇偮偺椺偼幚嵺傛傝彫偝偔側傝傑偡偑丄俲傗俬偼梊應僐僗僩偑係偲侾丄幚嵺偺僐僗僩傕係偲侾偲偄偆傛偆偵堦抳偟偰偄傑偡丅偟偐偟丄偳偺愡揰傕梊應僐僗僩偑幚嵺偺僐僗僩傪忋夞傞偙偲偼偁傝傑偣傫丅偟偨偑偭偰丄偙偺椺偼俙仏偺忦審傪枮偨偟偰偍傝丄俙仏傾儖僑儕僘儉偵傛傝丄嵟揔夝傪媮傔傞偙偲偑偱偒傑偡丅
椺戣恾俁丏俇偺桳岦僌儔僼偵懳偟偰奺扵嶕朄傪揔梡偟偨寢壥傪帵偟傑偡丅
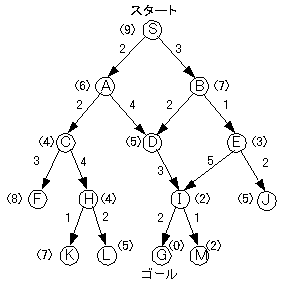
恾俁丏俇丂戝偒傔偺桳岦僌儔僼
廲宍扵嶕
僑乕儖傑偱偵揥奐偟偨愡揰丂侾侽
摼傜傟偨宱楬偼丂俽仺俙仺俢仺俬仺俧
宱楬偺僐僗僩偼丂侾侾
墶宍扵嶕
僑乕儖傑偱偵揥奐偟偨愡揰丂侾俁
摼傜傟偨宱楬偼丂俽仺俙仺俢仺俬仺俧
宱楬偺僐僗僩偼丂侾侾
暘婒尷掕朄
僑乕儖傑偱偵揥奐偟偨愡揰丂侾係
摼傜傟偨宱楬偼丂俽仺俛仺俢仺俬仺俧
宱楬偺僐僗僩偼丂侾侽
嶳搊傝朄
俠偺梊應僐僗僩偑俢偺傕偺傛傝彫偝偄偨傔偵幐攕偟偨丅
嵟椙桪愭扵嶕
僑乕儖傑偱偵揥奐偟偨愡揰丂俈
摼傜傟偨宱楬偼丂俽仺俙仺俢仺俬仺俧
宱楬偺僐僗僩偼丂侾侾
俙仏傾儖僑儕僘儉
僑乕儖傑偱偵揥奐偟偨愡揰丂俉
摼傜傟偨宱楬偼丂俽仺俛仺俢仺俬仺俧
宱楬偺僐僗僩偼丂侾侽
僐僗僩嵟椙偺宱楬傪摫偗偨偺偼暘婒尷掕朄偲俙仏傾儖僑儕僘儉偺傒偱丄俙仏傾儖僑儕僘儉偺傎偆偑丄偐側傝彮側偄庤悢偱尒偮偗偰偄傑偡丅偨偩偟丄梊應僐僗僩偑幚嵺偺僐僗僩偵姰慡偵堦抳偟偰偄傞偺側傜丄梋寁側寁嶼傪偟側偄嶳搊傝朄偑嵟懍偲側傝傑偡丅乮崱夞偼僑乕儖偵偨偳傝拝偔偙偲偡傜偱偒傑偣傫偱偟偨偑丅乯偟偐偟丄堦斒揑偵偼姰慡偵惓偟偄梊應僐僗僩傪媮傔傞偺偼柍棟偩偲巚傢傟傑偡丅戞堦丄偦偺傛偆側応崌偵偼扵嶕傪偡傞傑偱傕側偔懠偺傕偭偲偄偄曽朄偑偁傝偦偆偱偡偹丅
傑偨丄懠偵傕嵟椙桪愭扵嶕偼嶳搊傝朄偲摨偠忣曬偩偗傪棙梡偟偰偄側偑傜丄嶳搊傝朄偺夝偗側偐偭偨栤戣傪夝偄偰偄傑偡丅暘婒尷掕朄偼嵟揔宱楬傪媮傔偰偄傑偡偑丄寢壥偲偟偰偡傋偰偺愡揰傪揥奐偟偰挷傋偰偄傑偡丅
俙仏傾儖僑儕僘儉偼嵟椙偺夝傪傕偭偲傕懍偔媮傔偰偄傑偡偑丄扵嶕偵梡偄偰偄傞忣曬偺検傕堦斣懡偄偺偱丄摉慠偲偄偊偽摉慠偐傕偟傟傑偣傫偹丅